
ZD-1
羽球情蒐大數據—
基於電腦視覺之羽球比賽技術數據自動化分析與標註
學習
Anaconda虛擬環境建置
因為開發程式過程中,會有需要多樣模型建立並測試的環節;而其中各種不同的模型所要求的環境配置都有所不同;若將所有配置所需的套件裝在本機則會導致先前安裝過的套件與該模型所需的配置發生版本衝突導致程式發生錯誤無法運行。因此需利用Anaconda建置並使用虛擬環境來區分並不影響到本機的環境安裝套件配置,使用虛擬環境的好處是若有發生以上套件衝突及類似難以處理的情況發生時;能夠將該虛擬環境及套件一鍵刪除並重新建置,是開發過程中特別重要的一步驟。
CNN
卷積神經網路(Convolutional Neural Network,簡稱CNN)是深度學習的一個神經網路架構,由輸入層(Input Layer)、一個或多個卷積層(Convolution Layer)、池化層(Pooling Layer)以及頂部的全連接層(Fully Connected Layer)所組成。處理主要是經過資料進入輸入曾,透過卷積層進行特徵擷取,再由池化層做特徵壓,最後將矩陣格式資料展開來(攤平flatten)並把矩陣資料攤開來後變成一個神經元方式的排序,就會變成輸入層自變量(下圖中紅色區塊)

CNN模型概述
VIT
Vision Transformer(圖1)作為所有後續有用到之模型衍生的基礎,其原先主要為NLP領域所使用,影像分析則是透過預處理將圖片分割成好幾塊固定大小的patch,將每塊圖像進行線性嵌入並添加位置資訊後,將得到的向量序列送入Transformer Encoder(圖2)做特徵提取並分類。
Transformer Encoder(圖2)包含兩個模組:MSA(多頭注意力)、MLP(全連接層)blocks。
MSA與MLP前都會先應用一個Layernorm(LN)層,每塊之後有一個殘差連接。輸出結果會以向量作為圖像特徵,VIT在大型數據集的預訓練效果在大多數識別基準上,以較低的訓練成本達到最先進的水平。


▲VIT模型的概述(圖1)
▲Transformer Encoder(圖2)
SWIN
SWIN Transformer(圖1)主要分為四階段,先通過patch partition將圖像分割成非重疊的patch,第一階段通過線性嵌入層將patch映射到C,經過兩個SWIN-T block計算自注意力;第二階段進行patch merging降低token數量,一樣經過兩個SWIN-T block計算自注意力,將特徵轉至更深層;第三階段patch merging經過六個SWIN-T block計算自注意力;第四階段patch merging經過兩個SWIN-T block計算自注意力,將特徵轉至更深層,得到最終特徵。

▲SWIN Transformer模型的概述(圖1)

SWIN T-Block(圖2)和標準Transformer相似,只是替換了多頭注意路計算MSA為基於窗口移動的W-MSA和SW-MSA。
▲SWIN Transformer模型的概述(圖2)
Shifted Window based Self-Attention(圖3)採��用在小窗口內計算自注意力,不同於VIT是在整張圖片上計算,透過將window往右下(左上)移動兩個patch,並在心的特徵圖中再次劃分次方格,使window間可進行互動。
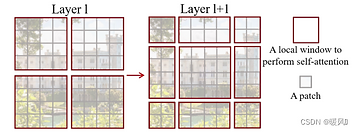
▲SWIN Transformer模型的概述(圖3)
PVT
-
分為四階段;每個階段生成不同尺度的特徵圖,並且每個階段都使用類似的結構。
-
使用一張大小為H×W×3的圖像作為輸入,切割成16個patch,然後將其通過線性投影轉換為HW/4^2×C1大小的嵌入式patch,再加上位置嵌入後通過一個L1層的Transformer encoder,得到一個尺寸為H/4×W/4×C1的特徵圖F1;F2,F3,F4皆為同樣的方式獲得,且輸入為前一階段的特徵圖。

▲Pyramid Vision Transformer模型的概述
YOLO

▲YOLOv8模型的概述

▲實際使用效果
TrackNet

▲TrackNet範例效果